





With so much content being created and shared nowadays, sometimes you just don’t have the time and resources to apply metadata (i.e. tag) to all those company assets. And this problem is more common than you think.
Here at Bynder, we were working with a client recently who had zero resources for tagging. It came to the point where the whole DAM project would’ve come to a complete halt without a dedicated tagging resource available. So, what did we do?
We made the decision to help them out in any way that we could. That is, by doing the tagging for them—which is not something we usually do for clients. Knowing that we were bending the rules a little bit to help keep the DAM implementation running smoothly, we ended up asking the client to sort their files into folders before sending them to Bynder, so we could tackle the tagging from a batch-level initially, with more specific item-level tagging coming from the client.
While the metadata record was not filled out completely, we were able apply over six different high-level metadata fields derived from information listed in the organized folder names (e.g. title, location, date, activity.) On top of that, it was made even easier because of all the embedded metadata and auto-applied metadata that took place during ingest—things we fortunately didn’t even have to fill out ourselves!
Nowadays, auto-tagging with the help of AI is becoming more commonplace within DAM solutions such as Bynder, which at least helps to ease the burden on customers when it comes to manually applying the metadata. A real timesaver, especially for digital collections that are brimming with photography.
Do you have the resources for tagging?
In reality, not everyone has the resources for tagging digital assets. What then? Solutions for this could be to prioritize by sorting assets into high-level, broad categories/folder before ingesting and begin tagging the most high-priority assets. But even if this is too much work, there are options available that can make the workload much more manageable:
- Outsource tagging to a third party that offers metadata application services
- Use suitable colleagues to apply metadata (a small amount of assets for a lot of people makes a difference!)
- Export data from an existing system and migrate your assets and metadata through a media import (this is only really an option for those who already have an existing DAM and good quality metadata)
The chart below is a nice guide for working out your own organization's capabilities for tagging:
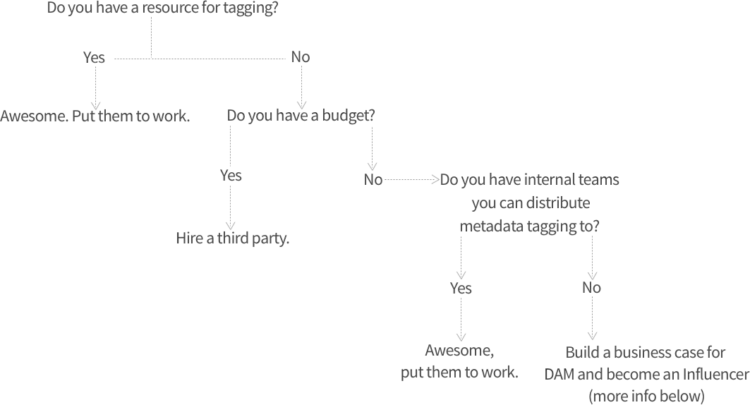
If you have no resources, budget, or colleagues to lend a helping hand, then you may need to be a bit more proactive and ask your organization: why not? We've created a handy guide on Building a business case for DAM: How to become an Influencer to help you become a real DAM advocate in your company and get the resources you need.
Batch-tagging vs item-level tagging
Firstly, what’s the difference? Batch-tagging is a quick way to apply high-level categories to your digital assets. That is, uploading your assets and globally apply the same set of metadata to the upload batch.
Item-level tagging is a more detailed application of metadata where you’re trying to fill out the entire metadata record for one or more assets. Unsurprisingly, it’s a lot more time-consuming, and you may be limited to a smaller group of assets that can be uploaded at the same time if they all have very different metadata that needs to be applied.
Note: Some DAM platforms, like Bynder, let you batch-tag and item-level tag at the same time when uploading—a huge time-saver!
How to batch-tag your assets
A great way to batch-tag your digital assets is to group them into similar categories. For example, uploading all event photography from a single event and applying metadata like event name, event date, and venue name.
Or perhaps you have an editorial photograph collection that are all from the same campaign or photoshoot. You’ll be able to quickly apply metadata for these assets like the name of the photographer, the name of the campaign, etc.
Great example assets for batch-tagging: events, campaigns, photoshoots, and generally, assets that were created for the same purpose and possibly even around the same time.
Best practice tip: Keep a record in an excel sheet or apply labels to the folders on the drive for which assets have been imported and minimally tagged, as well as which assets will need more detailed tagging later on.
Item-level tagging
Tagging assets at a more descriptive level is worth considering if you’ve got the resources to pull it off. After all, the more metadata you apply to a record, the easier it is for the user when trying to find it.
Let’s get tagging!
To recap, if you’re pressed for time and need to apply metadata in a hurry (but don’t rush it, it needs to be accurate!), aim to follow these steps:
- Prioritize the most important assets that need to be tagged
- Apply high-level categories in a batch
- Use all the product bells and whistles you can to pull in embedded metadata
- Begin a targeted item-level tagging project where you can:
- Appy in bulk item-level, additional metadata based on your subject matter expertise and saved searches (e.g. assets from a particular photographer that needs to have the field usage rights: “By request only” applied.)
- Complete item-level tagging for specific types of assets (i.e. tackle all brand materials like logos, fonts, and brand guidelines first as a priority.)
Check out the DIY DAM hub
If you’re looking for some more DAM tips and tricks, then check out our DAM best practices hub. Or if you are thinking of investing in DAM, click below to receive the DAM Comparison Guide.






